



An ideal decision log for remote work
"Everything Starts Out Looking Like a Toy" #101



Hi, I’m Greg 👋! I’ve written over 100 essays on product, data, and process where I noodle on an idea or a future product direction, often data that exists between systems.
We don’t talk enough about system “handshakes”, the expectations for workflow, and the jobs we expect data to do. Read more: What is Data Operations?
This week’s toy: a pen plotter that can be built with about $15 of materials in an hour. This is a great example of the impact of inexpensive computing when combined with use cases in the real world. Combine an inexpensive plotter with branded paper and you get custom giveaways, one-time drawings, or just a fun time. Edition 101 of this newsletter is here - it’s July 11, 2022.
The Big Idea
A short long-form essay about data things
⚙️ An ideal decision log for remote work

“How did we get here?” is a frequent refrain when considering a bug or some software behavior. As a Product Manager, you hope that the way a product behaves is consistent and related to an overall theory of interaction that matches the way things work elsewhere in the product. But that isn’t always the case. And often when you are reviewing work in progress or reviewing a bug based on long-ago decided behavior and discussion, the details of why that decision was made are missing, forgotten, or just nonexistent.
“Look at the PRD (Product Requirements Document)” is everyone’s default, and this is great if the PRD has been updated with every small decision that has been made in the software process from meetings, to emails, to Slack conversations and JIRA tickets. The reality is more often that the PRD represents our best guess at what the product was going to look like when we were designing it, and may not have been updated to match the way the feature behaves now, in the present.

We were promised flying cars
Everyone knows by now that we don’t have flying cars. At least not ones you can easily buy anyway.
The bigger point here is that a lot of decisions get made between the original process of creating and documenting a feature and the realization of that feature into code, testing, acceptance testing, and customer usage.
When you compare the original specification from the Product Requirements Document to the released product, it should match, even though things have changed, discussions have happened, and the features are not exactly the same. So why is it that QA teams (or Engineers, or Product Managers, or Executives) get surprised by the mismatch of expected features when compared to how things behave when they get released?
What we need: a decision log
When you find an inconsistency between the way things behave and the way you expected a product to work based on reading the requirements, what do you expect? Perfect information that would tell you every reason why the result looks a bit different than the original expectation.
If you had a log of all of the decisions that were made by stakeholders and a short write-up of why these decisions were made and the impact they made on the product, you’d be a long way toward understanding the difference between the product that was planned and the product that was released.
It’s easy - there’s even a Confluence Template you can install! But wait a minute.
Even if you know all of the relevant details for a decision, like:
What caused a decision point to occur
What was discussed
Who were the stakeholders and who ultimately made the decision
A summary of the discussion and anything that was added to technical debt to decide later
What was changed, and how the behavior of the feature or the product changes as a result
There remains a problem: this is partly a technology issue and partly a process issue. Decision logs get created when people realize that there is a decision that is being made and that they need to preserve the results of these decisions so that other people (later, not in the conversation, without context) could understand why this was done.
If the process is not easy or almost automatic, there’s no way the documentation will happen. The goal of the QA engineer to understand if the PRD is up to date is in peril if the organization doesn’t have a standard for when to update the product documentation in process so that everyone knows that something has changed. One software engineer tried to solve this using JIRA because a decision process seems like a lot of other issues and why not use the tools you have to solve the problems with managing process? But JIRA is a tool that works when people commit to using it. Decision logs don’t write themselves.
An ideal decision log
From the perspective of the people discussing something, an ideal decision log is pretty simple:
When: Right after a conversation that has happened (in Slack, in a meeting, in a comment about an issue)
What: Document the change and explain why. If there is a change to the original specification, also change the original specification and reference the comment
These simple requirements are partly aligned with the information people need later when they find the change and need to interpret it. From the perspective of people reading about a feature, an ideal decision log needs:
Clarity: what changed, who changed it, and why
Lineage: was this the first change or was it a subsequent change - how can I link this back to previous discussions?
Impact: was this a major or minor change? If we don’t know, what did we think at the time so we can measure the congruence of the impact later
Consistency: how do I know that this change has a similar amount of detail as another change I’m likely to read about
Context: what else was going on in the organization (or in the group) at the same time this decision was being made
The first three items above can be tackled with policy and process. It’s totally reasonable to expect that when we discuss material changes to features we need to update the product requirements documents. It’s also reasonable to capture some of the conversations happening at the time so that we start to have a historical record of what changed. We probably also know the impact of the decision we’re making, at least in an order of magnitude. Changing the color of an item on a screen is much different than changing a pricing model, updating a data retention policy, or removing a backward-compatible change.
Consistency and context are tricky items to solve with process. Ideally, you’d want metadata around the process to be tracked so that humans didn’t need to capture so much information. You would also want to track decisions over time so that you can understand things like how long do they take to resolve; are the decisions often reversed or never reversed; and whether decisions on certain topics derail or empower the team and produce negative or positive effects.
Here’s a simplifying idea. A lot of our conversations start in Slack or in another messaging tool.
If every time we realized we were making a decision, we:
Were able to start a process by making a contextual choice in Slack
Automatically open a temporary channel where the decision could be discussed in context
When completed, let the system know it was completed and write the results to a table where they could be related to a JIRA ticket, document, calendar item or similar
We would be creating consistency and context for our decisions. Here’s how it might look in Slack:
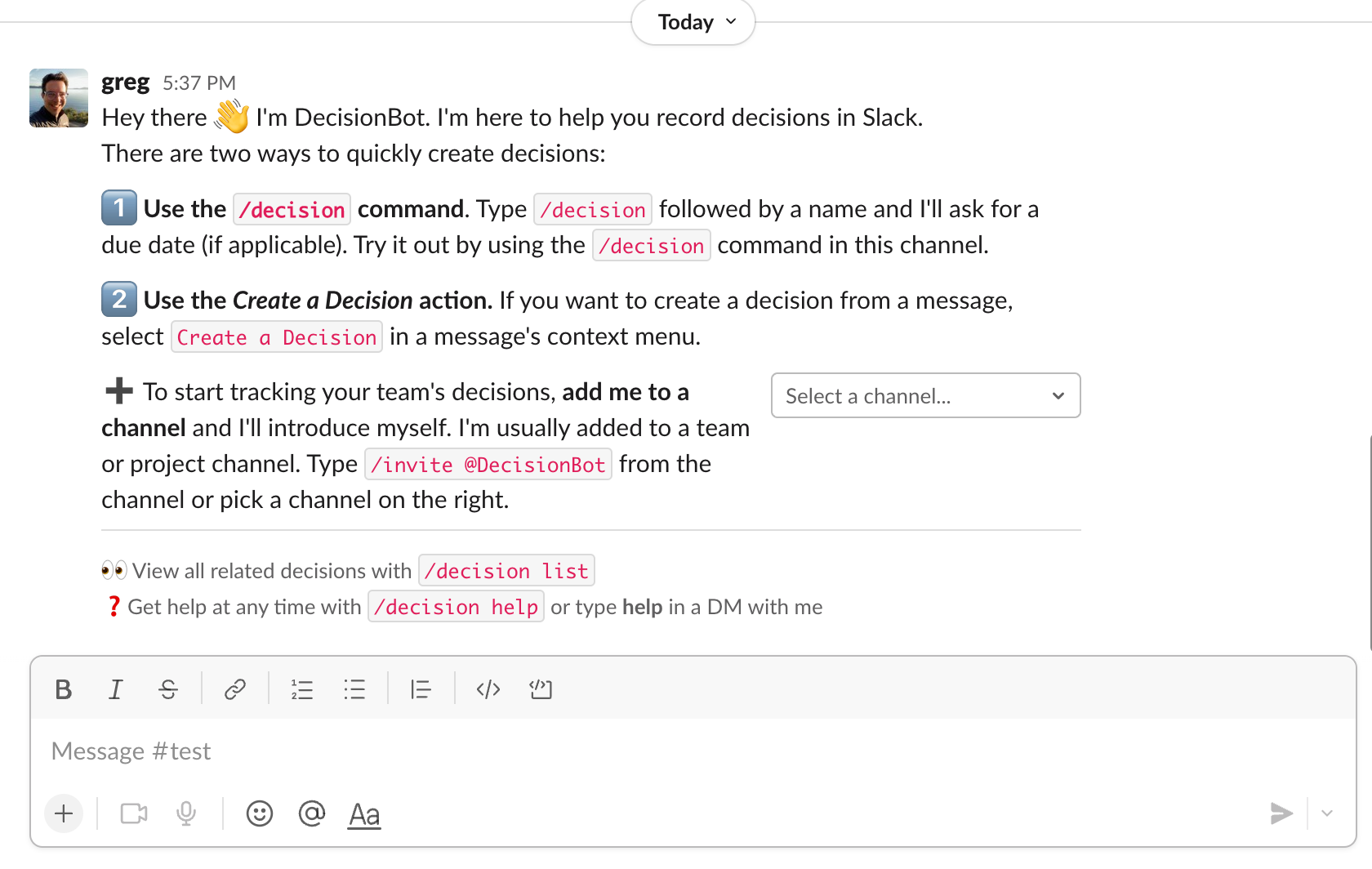
In this model, a /decision command or similar opens a channel where a few prompts structure the metadata, starting with:
Who owns (the person who started the decision item)
Who is responsible for deciding (optional, if this is going to be different than the recorder)
Who else to invite to this temporary area
What’s the summary of the item to be discussed (default to a trimmed-down version of the message where the context was added or set a title)
Relate a JIRA ticket (optionally)
When this is done, write this summary as a log to the JIRA ticket and also maintain a history of decisions so that we can create a weekly summary or produce the summary for an individual epic or story in a retrospective. Also, this could give you the prompt to update the PRD, closing the loop.
Having a decision log like this would make it much easier to know what changed, when it changed, why it changed, and what was the commentary around that decision. I’m pretty sure it’s easier to build than a flying car, and it’s going to take some incremental process improvements to implement this decision log as a regular part of our product development. For now, I’m going to start with updating the PRD every time I know I’m in a decision process and it ended.
What’s the takeaway? Remote work can be challenging when decisions are made by team members and not recorded in the places where those team members do their work. Why not make it easier, more transparent, and efficient by building a process to record decisions and prompt updates to needed documents inline with the current process? A decision log can make this easier.
Links for Reading and Sharing
These are links that caught my 👀
1/ Metrics you can use - I like this article by Sean Byrnes particularly because it points out the difference between vanity metrics and metrics that chart the path of your business. If you’re looking at second-order metrics, Sean writes, you are looking at the outputs of the business, not the items you’re immediately counting that can be gamed.

2/ Usability across platforms - Graeme Fulton’s piece on Touch-first cursors for tablets is an excellent read when thinking about user interaction and prompting the user for the next desired step. It’s pretty effective to highlight choices the user can make when browsing on a tablet. It’s very effective when you use that interaction to hint at other things they could do as their next step.
3/ A very useful database - sometimes, you just need to know how to find all of the types of wood you might be using in a project. The Wood Database is exactly that. I’m not sure how useful it is if you’re not contemplating a project for a woodshop, but it’s still a clever use of selecting metadata to identify the output of a search.
What to do next
Hit reply if you’ve got links to share, data stories, or want to say hello.
I’m grateful you read this far. Thank you. If you found this useful, consider sharing with a friend.
Want more essays? Read on Data Operations or other writings at gregmeyer.com.
The next big thing always starts out being dismissed as a “toy.” - Chris Dixon